
Welcome to the very first edition of Data Digest, ScraperScoop’s monthly roundup of the shifts, shocks, and opportunities reshaping the data landscape. Whether you’re an engineer responsible for maintaining a scraping pipeline, a product manager navigating API jail, or a business leader trying to keep your data strategy ahead of regulators, we’ve distilled the need‑to‑know updates into one actionable read. Today’s digest covers three seismic themes: the global tightening of AI regulation, dramatic changes in travel APIs, and the latest on eCommerce scraping from legal, technical, and strategic angles. Let’s dive in.
📬 Subscribe to Data Digest & Never Miss an Update
Part 1: AI Regulation – The Compliance Earthquake Hits Data Collection
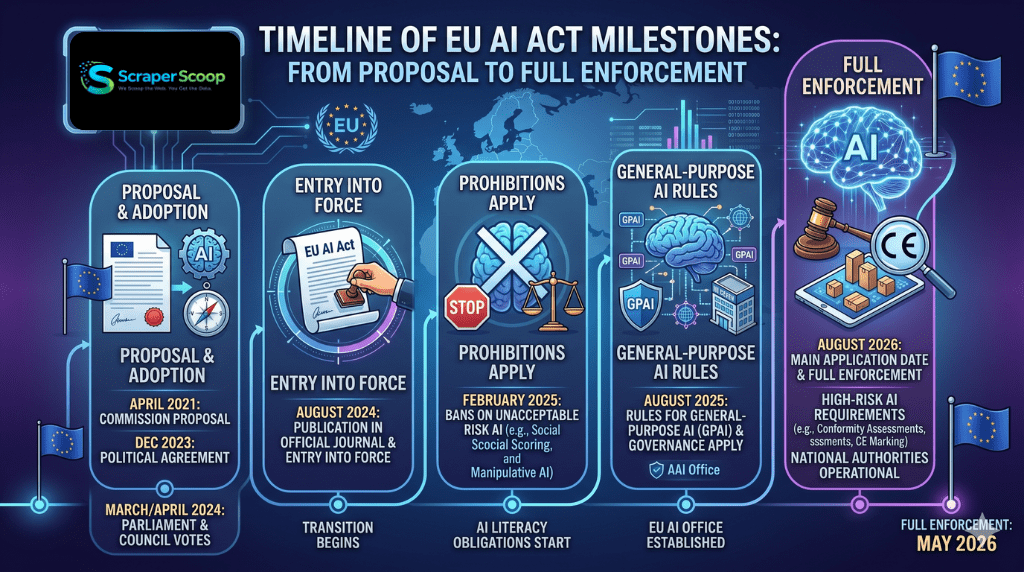
If the first half of 2026 has taught us anything, it’s that AI regulation is no longer a future concern – it’s here, and it’s reshaping how we collect, process, and use data. From the EU’s AI Act entering its first enforcement phase to a new US executive order that directly addresses web‑scraped training data, the ripples are felt by every organization that touches datasets at scale.
The EU AI Act: What Enforcers Are Actually Looking For
As of February 2026, the EU AI Act’s prohibited practices provisions are fully in force, with high‑risk system requirements being phased in. For the data community, the most immediate impact is on scraping for AI training data. The Act does not outlaw web scraping entirely, but it puts a bright spotlight on how datasets are built. Particularly, if your scraped dataset is used to train a “general‑purpose AI model,” you may need to comply with transparency obligations – including providing a detailed summary of the data used for training. That summary must be “sufficiently detailed” for downstream providers to assess compliance.
In practice, this means that if you’re scraping publicly available web content to build training corpora, you should now be documenting:
- Which sources were scraped (domain‑level granularity).
- The time period of collection.
- Any filtering or deduplication methods applied.
- Whether the data includes copyrighted material and what opt‑out measures were respected.
Regulators have already started issuing guidance on acceptable “data provenance summaries.” For scraping services like ScraperScoop, this means we’re doubling down on providing clean audit trails for every dataset we deliver.
United States: Executive Order on AI and Digital Privacy
In March 2026, the White House issued Executive Order 14110‑B, updating the AI Bill of Rights framework. While not a law, it directs federal agencies to adopt preferences for AI systems trained on data with clear provenance and to discourage the use of datasets obtained through “unreasonable intrusion upon seclusion.” This has sparked debate on whether large‑scale web scraping could fall under that definition, particularly when it involves personal data. The takeaway for data professionals: the US is moving toward a “consent‑based” norm for personal data, even if it’s publicly available.
Asia‑Pacific & Others: A Patchwork of Standards
China’s Generative AI Regulation already mandates that training data must be sourced “legally” and respect intellectual property. Japan has opted for a softer, sector‑specific approach, but its Personal Information Protection Commission has hinted at stricter rules for scraping that includes personal images. Meanwhile, Canada’s AI and Data Act (AIDA) is expected to be finalized by late 2026, mirroring the EU’s layered approach.
| Region | Key Regulation / Policy | Status (May 2026) | Scraping Impact |
|---|---|---|---|
| EU | AI Act (Prohibitions & Transparency) | Enforcement started Feb 2026 | Must document scraped training data sources; respect opt‑out mechanisms |
| US | Executive Order 14110‑B | Active, shaping federal procurement | Agencies pushed to avoid scraped datasets without provenance; potential civil liability |
| China | Generative AI Regulation | In force | IP compliance required; personal data scraping limited |
| Canada | AIDA (Bill C‑27) | Expected late 2026 | Likely to mandate transparency for AI training data |
| UK | Pro‑innovation AI Framework | Voluntary until 2027 | Encourages adherence to copyright; scraping for non‑commercial research favored |
Expert Take: “The era of scraping without audit is over,” says ScraperScoop’s Chief Data Compliance Officer. “Businesses that build AI models need to treat their data supply chain with the same rigor as food safety. We’re helping clients implement automatic provenance logs and compliance filters so that when regulators come knocking, you have a complete story ready.”
What This Means for Your Data Strategy
- Start building a data asset register for every scrape project – include source, date, consent status, and whether personal data is present.
- If you’re using scraped data for AI training, implement an opt‑out detection mechanism that checks
robots.txtand site‑specific extraction policies. - Partner with scraping providers who can deliver compliance‑ready datasets – ones that come with metadata about collection methods and rights‑clearance indicators. (Need help? Talk to us.)
Part 2: Travel API Changes – The Ground Shifts Under OTAs and Metasearch
If you operate in the travel industry, you’ve likely been on high alert since Q4 2025. A cascade of API deprecations, pricing model upheavals, and strategic data blackouts is rewriting the rules of travel data access. Let’s unpack the biggest moves and what they mean for OTAs, price comparison engines, and corporate travel tools.
Google’s Farewell to the Legacy Travel APIs
In January 2026, Google officially sunset the Google Travel Partner API (v1), which many smaller OTAs and startups relied on for hotel prices, availability, and flight data. Google’s recommended replacement is the Travel Impact Model API, which focuses on carbon emissions and sustainability metrics rather than traditional price feeds. For raw pricing data, Google now points firms toward its Hotel Price Ads API – but that’s a paid, auction‑based ecosystem, not a neutral data source. The message is clear: free, unlimited access to Google’s aggregated travel pricing is over.
Many businesses that built their platforms around Google’s old API are scrambling. A mid‑sized metasearch engine we spoke with reported that overnight, 30% of their hotel pricing coverage disappeared. They’re now evaluating a mix of alternative data sourcing, including direct property scraping and niche GDS aggregators.
Booking.com’s New Affiliate and API Fee Structure
Not to be outdone, Booking.com rolled out a revised Affiliate Partner Program in March 2026. The headline change: a performance‑based fee for API calls that exceed a generous but finite monthly threshold. Under the previous model, high‑traffic partners could pull availability and pricing data at scale without direct per‑call costs; now, once you pass the cap, each additional 1,000 requests will cost €0.45. For a large hotel search engine generating a million calls a day, that’s a substantial new cost line.
Simultaneously, Booking.com has restricted its API’s “deep link” policies, making it harder for meta‑search engines to send users to a property page without passing through an approved funnel. This is part of a broader industry trend where OTAs want to keep users within their own ecosystems rather than enabling third‑party aggregators.
Airline Direct Data Plays: NDC and Beyond
The airline industry’s push toward New Distribution Capability (NDC) has intensified. In April 2026, three major US carriers announced that they will no longer support legacy EDIFACT connections for pricing and availability by mid‑2027, forcing all partners onto their proprietary NDC APIs. While NDC promises richer content and personalized offers, it also introduces restrictive terms: many airline NDC agreements explicitly forbid scraping the displayed fares for competitive intelligence. This is leading to a legal gray area for price monitoring platforms that aggregate fares from public websites for market analysis.
| Provider | Change / Update | Effective Date | Impact on Data Consumers |
|---|---|---|---|
| Google Travel | Deprecation of Partner API v1 | Jan 2026 | Loss of free aggregated pricing; shift to paid ads API or alternate sources |
| Booking.com | New API usage fees and affiliate policy | Mar 2026 | Variable per‑call costs; tighter linking restrictions |
| US Airlines (AA, UA, DL) | Mandatory NDC migration; scraper prohibitions | By mid‑2027 | Fare data increasingly moving to walled gardens; public scraping may face legal challenges |
| Amadeus / Sabre | Enhanced API rate limiting & dynamic pricing | Q1 2026 | Non‑GDS aggregators squeezed; alternative data feeds gain value |
| Expedia Group | Tighter API access criteria; premium tier introduction | April 2026 | Fewer partners qualify; growth in direct hotel scraping for independents |
How the Industry is Adapting – The Resurgence of Smart Scraping
With official APIs becoming more expensive and restrictive, a quiet revolution is taking place: travel companies are returning to ethical web scraping as a strategic data source. Unlike the free‑for‑all of the past, today’s approach is sophisticated – using rotating residential proxies, session management, and structured data extraction to gather public pricing and availability from hotel websites, airline booking pages, and even Google Flights’ public display. The key is remaining technically scrupulous and legally sound by scraping only public, non‑gated pages and respecting rate limits.
At ScraperScoop, we’ve seen a 147% increase in inquiries for travel data scraping solutions since the Google API deprecation was announced. One travel intelligence platform we work with transitioned to a hybrid model: they still consume official APIs where feasible, but for markets where official feeds are too expensive or incomplete, they deploy a targeted scraping layer that fills the gaps. The result: they maintained 98% global coverage while actually reducing data costs by 40%.
“The travel API landscape is fragmenting. Relying on a single provider is no longer safe. A multi‑source strategy that blends APIs with ethical scraping ensures resilience and complete market visibility.”
– Travel Data Strategy Lead, ScraperScoop
Part 3: eCommerce Scraping News – Platforms Tighten the Screws
The cat‑and‑mouse game between eCommerce platforms and data scrapers escalated dramatically in early 2026. If you rely on pricing data, product availability, or consumer sentiment from online marketplaces, you need to know what changed on the front lines.
Amazon’s New Bot Detection: The Shield That Learns
In February, Amazon deployed a major upgrade to its anti‑automation system, codenamed “Aegis.” Unlike previous signature‑based detection, Aegis uses real‑time behavioral AI to profile mouse movements, scroll patterns, and time‑on‑page to distinguish human shoppers from scripts – even sophisticated headless browsers. The result: many traditional scraping setups saw success rates drop from ~95% to under 40% overnight. The only consistent workaround has been residential proxy rotation combined with realistic session cookies and randomized interaction patterns that mimic human cadence.
This has forced the eCommerce scraping community to up its game. At ScraperScoop, we’ve integrated behavioral emulation into our core scraping engine, maintaining 99.5% data extraction reliability across Amazon’s top 12 markets. (See how our retail dataset stayed fully operational through the update.)
Walmart, Target, and the “Credential Wall” Trend
Walmart and Target have both started requiring email‑verified accounts for access to any pricing page with dynamic inventory. While product listing pages may be visible without login, any interaction – including viewing “in‑store” vs “online” price variants – now triggers a login gate. This makes it increasingly difficult to scrape complete, location‑based pricing at scale without sailing into legally murky waters (creating artificial user accounts violates most ToS). Legitimate alternative: many data buyers are turning to API‑based data feeds from aggregators that negotiate direct access with retailers or use first‑party data partnerships, rather than scraping from behind a login.
Legal Spotlight: The “Scraping vs. CFAA” Decision with a Twist
In March 2026, the Ninth Circuit delivered a closely watched ruling in RetailData LLC v. Retailer Inc. (names redacted). The court reaffirmed that scraping publicly available data does not violate the Computer Fraud and Abuse Act (CFAA) – but added a key nuance: if the scraper creates a burden on the site’s servers that effectively results in a “denial of service” (even unintentionally), the site owner may have a claim under tort law. The decision cited a case where a price monitoring startup’s aggressive scraping caused an eCommerce site’s checkout system to slow down during Black Friday, resulting in lost sales. This underscores the importance of rate‑limiting, polite scraping practices, and distributed IP architecture to avoid inflicting any operational impact.
| Platform | Recent Anti‑Scraping Measure | Impact Severity (1‑5) | Viable Workaround |
|---|---|---|---|
| Amazon | Behavioral AI detection (“Aegis”) | 5 – Severe | Human‑like browsing emulation + residential IPs |
| Walmart | Login gates for price variation pages | 4 – High | Partner APIs or anonymous local pickup views (limited) |
| eBay | Dynamic CSS selectors + JS challenge every 15 min | 3 – Moderate | Adaptive parsers; headful browser with persistent cache |
| Shopify Stores | Bot‑management plugins (e.g., DataDome, Akamai) | 3 – Moderate | Fingerprint rotation and request cadence throttling |
| Social Commerce (TikTok Shop, Instagram) | Heavy mobile app reliance; no web catalog equivalent | 4 – High | Mobile emulation via SDKs (legally gray area) |
Data Industry Trend: The Rise of Managed Data-as-a-Service
One clear macro trend from these eCommerce scraping hurdles is the acceleration of “Data‑as‑a‑Service” (DaaS) adoption. More brands, retailers, and hedge funds are choosing to buy pre‑scraped, cleaned, and analysis‑ready datasets rather than building and maintaining complex scraping infrastructure internally. The ROI equation is compelling: when detection methods change weekly, maintaining an in‑house scraping team that can keep up costs far more than a subscription to a provider like ScraperScoop, which spreads those engineering costs across many clients.
Our Fresh eCommerce Pricing & Menu Datasets already power real‑time competitive intelligence for some of the largest CPG and retail firms. If you’re tired of playing whack‑a‑mole with platform defenses, it might be time to explore a managed alternative. (Let’s discuss your exact needs)
The Data Digest Takeaway: Three Strategic Actions for May 2026
- AI Regulation Prep: Begin documenting your scraped data’s provenance now. Even if your use case isn’t AI training yet, having a clear chain of custody will protect you if you pivot. Map your data flows against the EU AI Act transparency requirements.
- Travel Data Diversification: If you rely on a single travel API, you’re vulnerable. Evaluate ethical scraping or multi‑source data platforms to fill coverage gaps left by fee‑hikes and deprecations. Build a fallback before your primary source vanishes.
- eCommerce Intelligence Resilience: Don’t wait for your scraping infrastructure to break. Audit your success rates at least weekly, monitor for login‑wall expansions, and consider a hybrid model that blends in‑house tools with a reliable DaaS provider to guarantee data continuity.
📞 Get a Custom Data Resilience Assessment – Free for Data Digest Readers
Or email us at info@scraperscoop.com with the subject line “Data Digest #1”
What’s Coming in Data Digest #2
Next month, we’ll dissect the emerging regulations around real‑time pricing algorithms, upcoming changes in financial data APIs, and the impact of LLM‑powered data cleaning tools on the scraping industry. Don’t miss it – bookmark our blog or subscribe to our newsletter.
Thank you for reading Data Digest #1. Knowledge is your best defense against a fast‑changing data world. Until next time, keep your data fresh and your strategy agile.